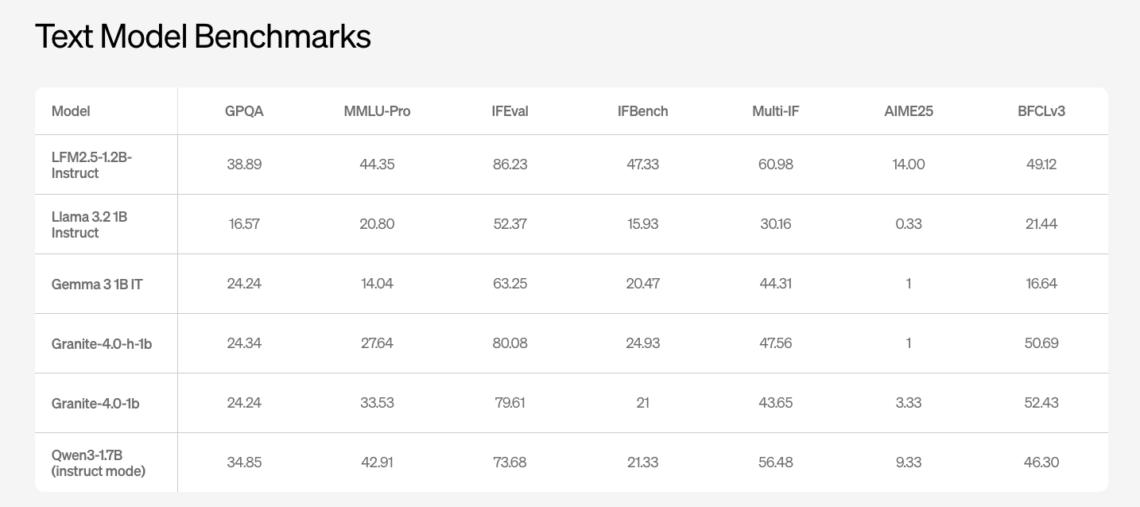
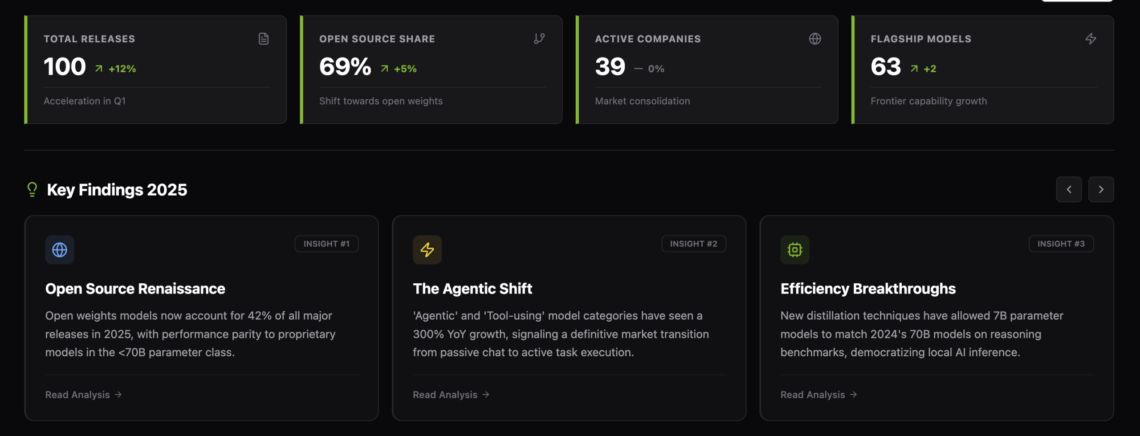
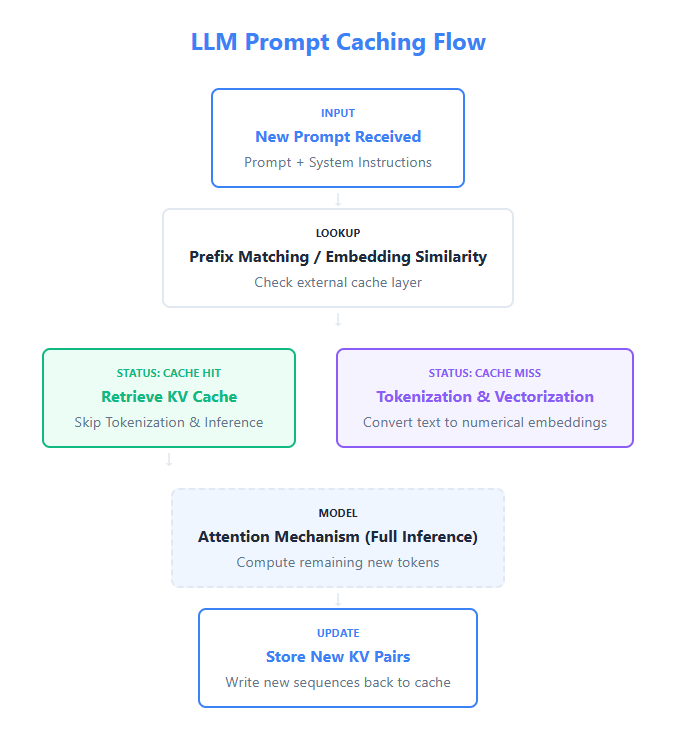
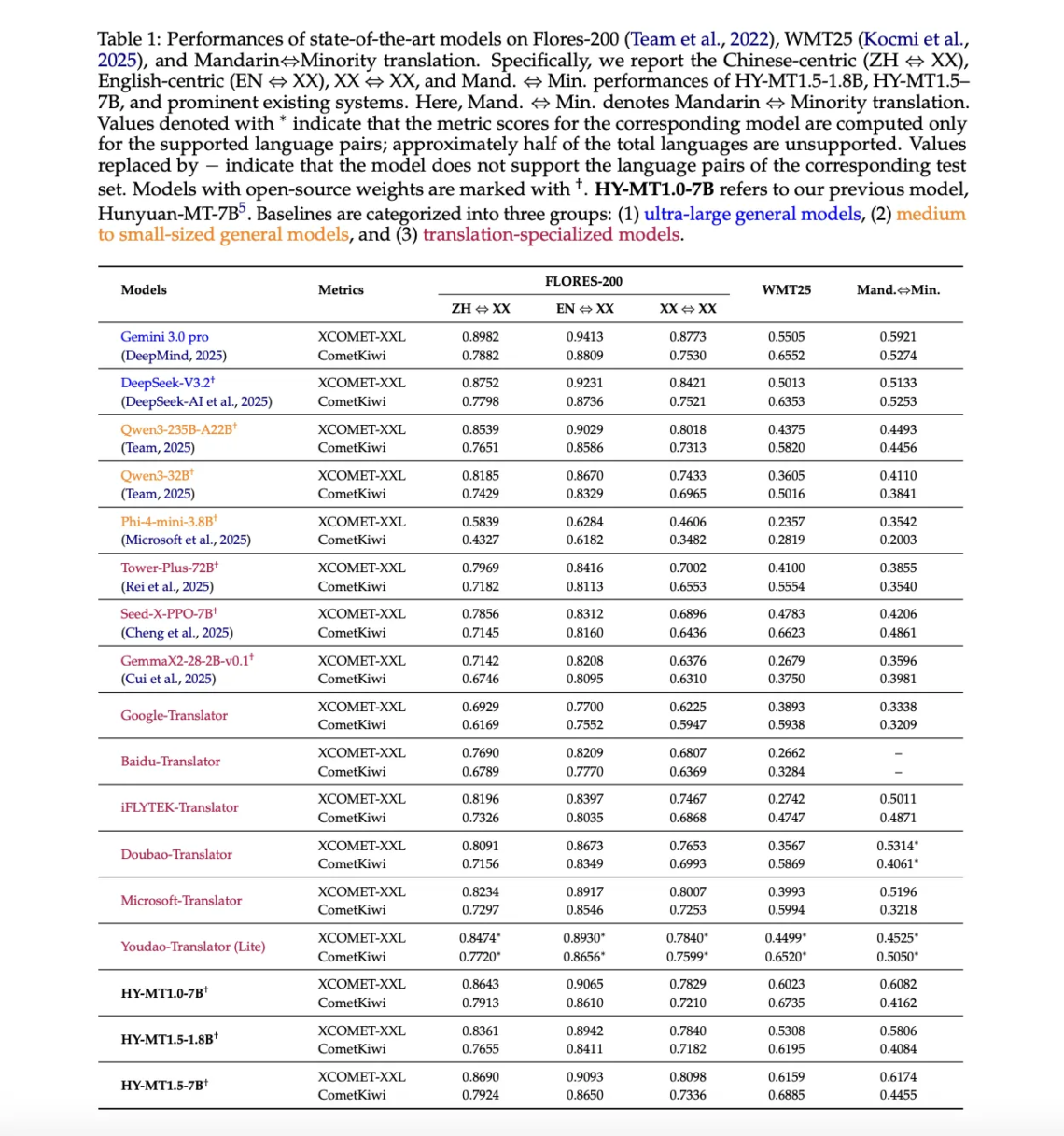
In this tutorial, we build a genuinely advanced Agentic AI system using LangGraph and OpenAI models by going beyond simple planner, executor loops. We implement adaptive deliberation, where the agent dynamically decides between fast and deep reasoning; a Zettelkasten-style agentic memory graph that stores atomic knowledge and automatically links related experiences; and a governed tool-use mechanism that enforces constraints during execution. By combining structured state management, memory-aware retrieval, reflexive learning, and controlled tool invocation, we demonstrate how modern agentic systems can reason, act, learn, and evolve rather than respond in a single pass. Check out the FULL CODES here. !pip -q…